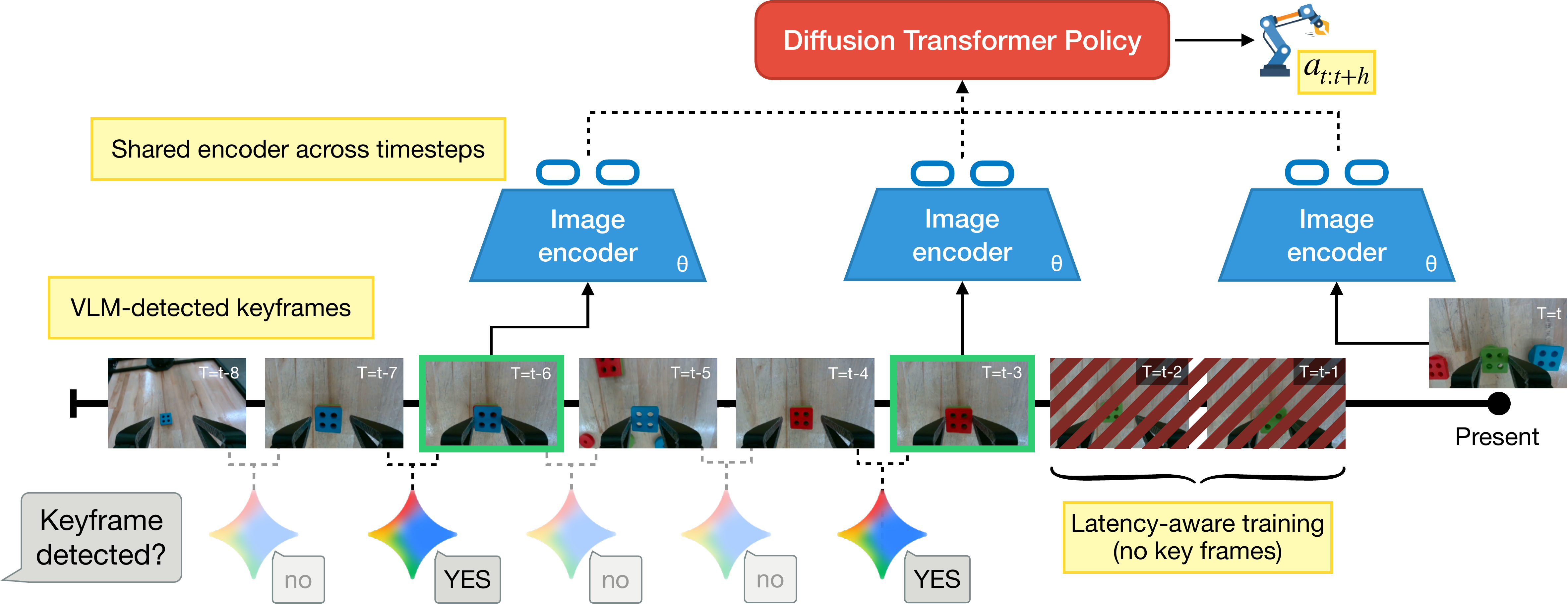
Naive History Conditioning Fails
Conditioning policies on subsampled past observations seems natural, but it leads to failures across diverse tasks. Policies latch onto spurious correlations in training histories that do not generalize to out-of-distribution rollouts at deployment time.
We ran experiments in simulation to understand why this happens. We probe how well policies understand the current history state (by training a separate head that predicts history state with a stop-gradient, and comparing accuracies). We find that methods that condition on subsampled past histories accurately predict history state in unseen but in-distribution trajectories, but fail on trajectories from their own policy's rollouts, which are slightly out-of-distribution.
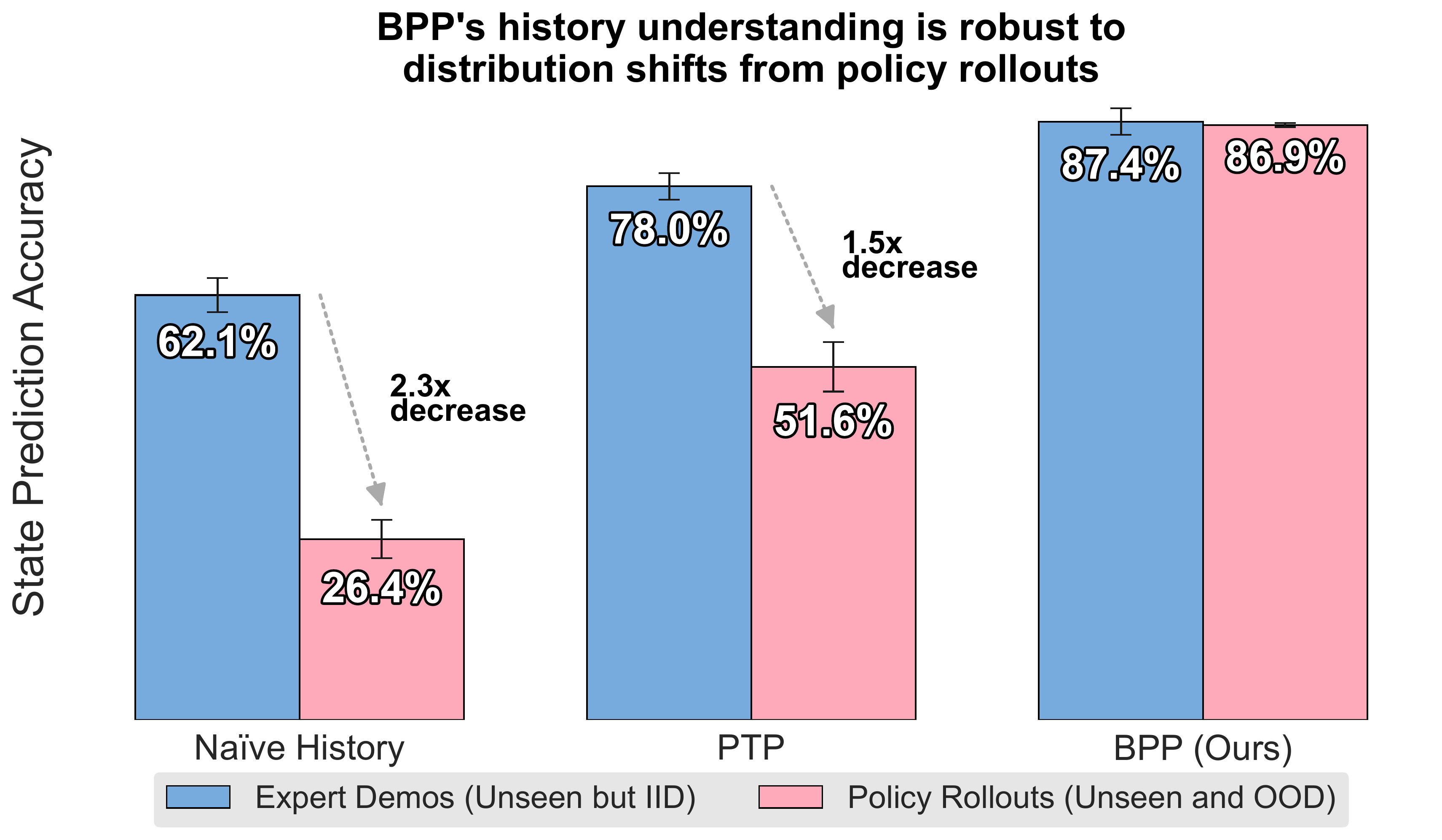
History understanding degrades on policy rollouts (out-of-distribution).
Regularizations like Past Token Prediction (PTP) can help, but the problem persists, both in history understanding and evaluation performance (see results below).
Regularization does not fix lack of coverage over possible histories.